一份详细注释的go Mutex源码
带注释的源码在文章最后
带注释的源码在文章最后。。。
本文基于go 1.9.3。从go的Mutex源码中看下互斥锁的基本实现和考虑是怎样的。有错误地方欢迎指正。
- CAS原子操作。
- 需要有一种阻塞和唤醒机制。
- 尽量减少阻塞和唤醒切换成本。
- 锁尽量公平,后来者要排队。即使被后来者插队了,也要照顾先来者,不能有“饥饿”现象。
先看3,4点。再看2,1点。最后是源码。
尽量减少阻塞和唤醒切换成本
减少切换成本的方法就是不切换,简单而直接。
不切换的方式就是让竞争者自旋。自旋一会儿,然后抢锁。不成功就再自旋。到达上限次数才阻塞。
自旋就是CPU空转一定的时钟周期
不同平台上自旋所用的指令不一样。例如在amd64平台下,汇编的实现如下
1
2
3
4
5
6
7
8
|
TEXT runtime·procyield(SB),NOSPLIT,$0-0
MOVL cycles+0(FP), AX
again:
// 自旋cycles次,每次自旋执行PAUSE指令
PAUSE
SUBL $1, AX
JNZ again
RET
|
是否允许自旋的判断是严格的。而且最多自旋四次,每次30个CPU时钟周期。
能不能自旋全由这个条件语句决定if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter)。
翻译下,就是下面的条件都满足,才允许自旋。
- 锁已被占用,并且锁不处于饥饿模式。
- 积累的自旋次数小于最大自旋次数(active_spin=4)。
- cpu核数大于1。
- 有空闲的P。
- 当前goroutine所挂载的P下,本地待运行队列为空。
可以看到自旋要求严格,毕竟在锁竞争激烈时,还无限制地自旋就肯定会影响其他goroutine。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
const active_spin = 4
func sync_runtime_canSpin(i int) bool {
// 自旋次数不能大于 active_spin(4) 次
// cpu核数只有一个,不能自旋
// 没有空闲的p了,不能自旋
if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 {
return false
}
// 当前g绑定的p里面本地待运行队列不为空,不能自旋
if p := getg().m.p.ptr(); !runqempty(p) {
return false
}
return true
}
|
锁模式介绍
上面的出现了两个常量,mutexStarving和mutexLocked。它们与锁对象结构有关。比较基础,这里介绍一下。
1
2
3
4
5
|
type Mutex struct {
// [阻塞的goroutine个数, starving标识, woken标识, locked标识]
state int32
sema uint32
}
|
Mutex结构简单的就只有两个成员变量。sema是信号量,下文会介绍到。这里主要介绍state的结构。

一个32位的变量,被划分成上图的样子。右边的标识也有对应的常量
1
2
3
4
5
6
|
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving
mutexWaiterShift = iota
)
|
含义如下:
- mutexLocked对应右边低位第一个bit。值为1,表示锁被占用。值为0,表示锁未被占用。
- mutexWoken对应右边低位第二个bit。值为1,表示打上唤醒标记。值为0,表示没有唤醒标记。
- mutexStarving对应右边低位第三个bit。值为1,表示锁处于饥饿模式。值为0,表示锁存于正常模式。
- mutexWaiterShift是偏移量。它值为3。用法是state>>=mutexWaiterShift之后,state的值就表示当前阻塞等待锁的goroutine个数。最多可以阻塞2^29个goroutine。
Mutex锁分为两种模式,正常模式 和 饥饿模式。
正常模式下,对于新来的goroutine而言,它有两种选择,要么抢到了锁,直接执行;要么抢不到锁,追加到阻塞队列尾部,等待被唤醒的。
饥饿模式下,对于新来的goroutine,它只有一个选择,就是追加到阻塞队列尾部,等待被唤醒的。而且在该模式下,所有锁竞争者都不能自旋。
除了这两种模式。还有一个Woken(唤醒标记)。它主要用于自旋状态的通知和锁公平性的保证。分两个角度理解:
一、新的goroutine申请锁时,发现锁被占用了。但自己满足自旋条件,于是自己自旋,并设置上的Woken标记。此时占用锁的goroutine在释放锁时,检查Woken标记,如果被标记。哪怕现在锁上面的阻塞队列不为空,也不做唤醒。直接return,让自旋着的goroutine有更大机会抢到锁。
1
2
3
|
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
|
二、释放锁时,检查Woken标记为空。而阻塞队列里有goroutine需要被唤醒。那么在唤醒时,同时标记锁Woken。这里可能有疑问,原来没有Woken标记,为什么在唤醒一个goroutine要主动标记呢?目的是保证锁公平。
考虑这样的场景:现在阻塞队列里只有一个goroutine。把它唤醒后,还得等调度器运行到它,它自己再去抢锁。但在调度器运行到它之前,很可能新的竞争者参与进来,此时锁被抢走的概率就很大。
这有失公平,被阻塞的goroutine是先到者,新的竞争者是后来者。应该尽量让它们一起竞争。
1
2
|
// 唤醒一个阻塞的goroutine,并把锁的Woken标记设置上
new = (old - 1<<mutexWaiterShift) | mutexWoken
|
设置Woken标记后,state就肯定不为零。此时新来的竞争者,在执行Lock()的fast-path时会失败,接下来就只能乖乖排队了。
1
2
3
4
5
6
7
8
9
|
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
// Woken标记设置后,这里的CAS就会为false
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
// ...
return
}
// 接下来在阻塞里排队
}
|
小总结:为了减少切换成本,短暂的自旋等待是简单的方法。而竞争者在自旋时,要主动设置Woken标记。这样释放者才能感知到。
锁尽量公平
为什么不是绝对公平?要绝对公平的粗暴做法就是在锁被占用后,其它所有竞争者,包括新来的,全部排队。
但排队的问题也很明显,排队阻塞唤醒的切换成本(这是损耗性能的潜在的隐患,下面Mutex的问题有举例)。假如临界区代码执行只需要十几个时钟周期时,让竞争者自旋等待一下,立刻就可以获得锁。减少不必要的切换成本,效率更高。
尽量公平的结果就是阻塞的竞争者被唤醒后,也要与(正在自旋的)新竞争者抢夺锁资源。
go使用三种手段保证Mutex锁尽量公平:
- 上面介绍的,在锁释放时,主动设置Woken标记,防止新的竞争者轻易抢到锁。
- 竞争者进阻塞队列策略不一样。新的竞争者,抢不到锁,就排在队列尾部。先来竞争者,从队列中被唤醒后,还是抢不到锁,就放在队列头部。
- 任何竞争者,被阻塞等待的时间超过指定阀值(1ms)。锁就转为饥饿模式。这时锁释放时会唤醒它们,手递手式把锁资源给它们。别的竞争者(包括新来的)都抢不到。直到把饥饿问题解决掉。
饥饿问题是会积压的。要尽快解决。举个例子解释一下:
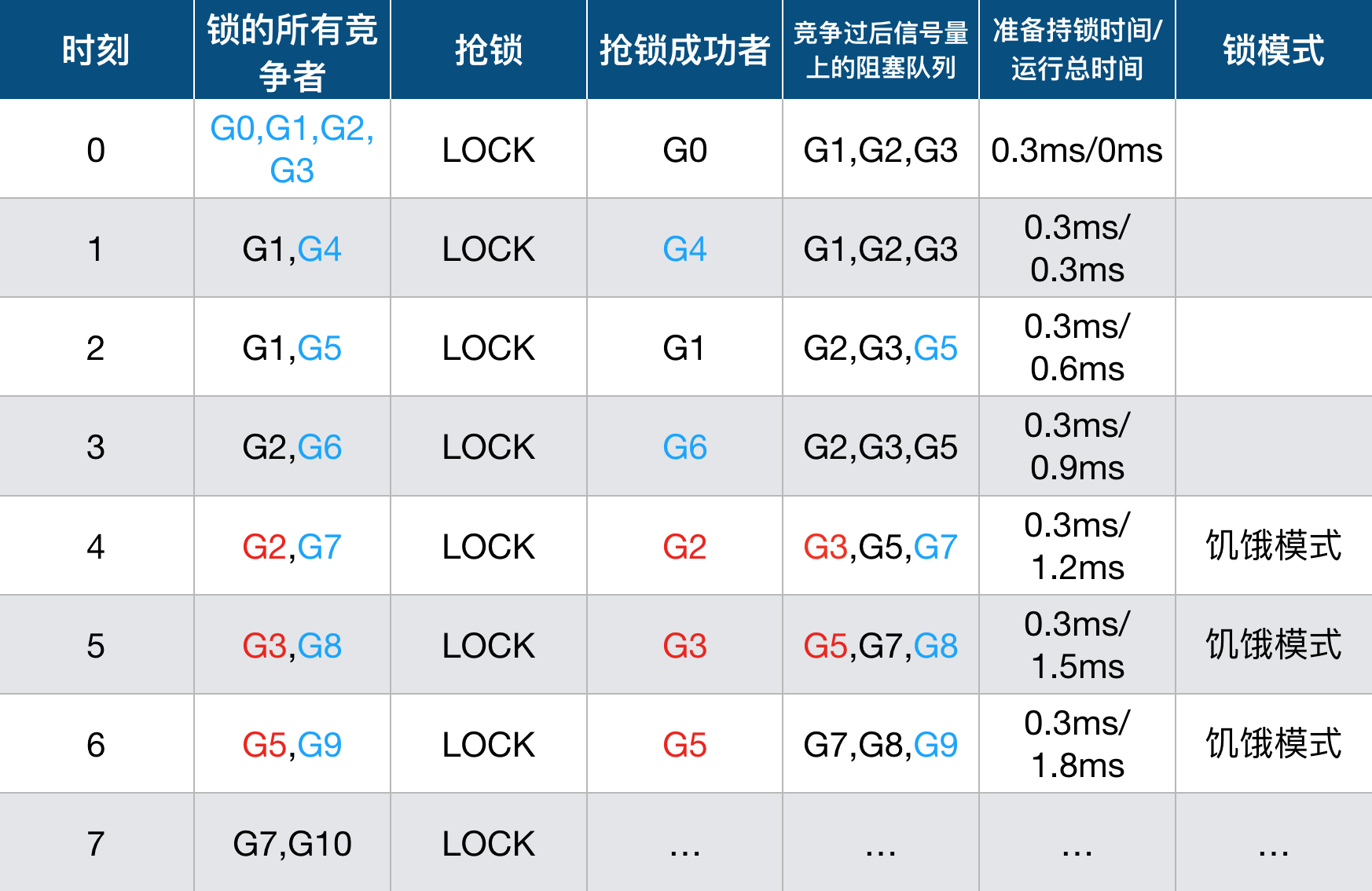
蓝色是新竞争者,红色是阻塞等待时间超过阀值的竞争者。每次持锁时间是0.3ms。
只要有竞争者阻塞超时了,锁就会转换为饥饿模式。饥饿模式下,所有的新竞争者都得排队。
图中时刻4中的G3就是被积压的。如果时刻0中的竞争者更多时,并且抢锁顺序不变。那么时刻4的积压就更严重。
同时反映出一个问题。
Mutex带来的问题
假设在业务某个场景中,对每个请求都需要访问某互斥资源。使用Mutex锁时,如果QPS很高,阻塞队列肯定会很满。虽然QPS可能会降,但请求是持续的。
新来的请求,在访问互斥资源时有可能抢锁成功,后来者胜于先到者。这种情况持续发生的话,就会导致阻塞队列中所有的请求得不到处理,耗时增高,直至超出上游设置的超时时间,一下子失败率突增,上游再影响它的上游,引起连锁反应进而服务故障异常。
解决方案要根据实际业务场景来优化。削减锁的粒度;或者使用CAS的方式进队列,然后阻塞在通道上;或者使用无锁结构等等。
阻塞在通道而不是阻塞的锁上,是因为go的runtime对待锁唤醒和通道唤醒goroutine的效率是不一样的。这也引出了还有一种方案是改runtime,让锁唤醒的goroutine更快地得到执行。毕竟上面问题点是被唤醒的goroutine和新的goroutine在竞争中不能保证稳胜,被唤醒的goroutine会有一个调度耗时,减少耗时就有可能提高竞争成功率。
阻塞和唤醒机制
go的阻塞和唤醒是semacquire和semrelease。虽然命名上是sema,但实际用途却是一套阻塞唤醒机制。
1
2
|
// That is, don't think of these as semaphores.
// Think of them as a way to implement sleep and wakeup
|
其实这个阻塞和唤醒机制,完全可以另写一篇。不过配合Mutex锁的理解这儿就先简单介绍下。
go的runtime有一个全局变量semtable,它放置了所有的信号量。
1
2
3
4
5
6
7
|
var semtable [semTabSize]struct {
root semaRoot
pad [sys.CacheLineSize - unsafe.Sizeof(semaRoot{})]byte
}
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags)
func semrelease1(addr *uint32, handoff bool)
|
每个信号量都由一个变量地址指定。Mutex就是用成员sema的地址。
在阻塞时,调用semacquire1,把地址(addr)传给它。
如果addr大于1,并且通过CAS减一成功,那就说明获取信号量成功。不用阻塞。
否则,semacquire1会在semtable数组中找一个元素和它对应上。每个元素都有一个root,这个root是Treap树(ACM同学应该熟悉)。
最后addr变成一个树节点,这个树节点,有自己的一个队列,专门放被阻塞的goroutine。叫它阻塞队列吧。
这个阻塞队列是个双端队列,头尾都可以进。
semacquire1把当前goroutine相关元数据放进阻塞队列之后,就挂起了。
semrelease1是给addr CAS加一。
如果坚持发现当前addr上有阻塞的goroutine时,就取一个出来,唤醒它,让它自己再去semacquire1。这是handoff为false的情况。
但handoff为true的话,就尝试手递手地把信号量送给这个goroutine。等于说goroutine不用再自己去抢了,因为自己再去抢有可能抢不到。
最后semrelease1会把取出来的这个goroutine挂在当前P的本地待运行队列尾部,等待调度执行。
就是这样,在获取不到Mutex锁时,通过信号量来阻塞和唤醒goroutine。
CAS原子操作
CAS就是基本的原子操作。没什么好说的。
例如在amd64上,go的汇编实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
TEXT ·CompareAndSwapUint32(SB),NOSPLIT,$0-17
MOVV addr+0(FP), R1
MOVW old+8(FP), R2
MOVW new+12(FP), R5
SYNC
cas_again:
MOVV R5, R3
LL (R1), R4
BNE R2, R4, cas_fail
SC R3, (R1)
BEQ R3, cas_again
MOVV $1, R1
MOVB R1, swapped+16(FP)
SYNC
RET
cas_fail:
MOVV $0, R1
JMP -4(PC)
|
源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
|
type Mutex struct {
// [阻塞的goroutine个数, starving标识, woken标识, locked标识]
// [0~28, 1, 1, 1]
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken // 唤醒标记
mutexStarving // 饥饿模式
mutexWaiterShift = iota // 位移数
starvationThresholdNs = 1e6 // 阻塞时间阀值1ms
)
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
// 尝试CAS上锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
// 上锁成功,直接返回
return
}
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// 进入到这个循环的,有两种角色goroutine
// 一种是新来的goroutine。另一种是被唤醒的goroutine。所以它们可能在这个地方再一起竞争锁
// 如果新来的goroutine抢成功了,那另一个只能再阻塞着等待。但超过1ms后,锁会转换成饥饿模式
// 在这个模式下,所有新来的goroutine必须排在队伍的后面。没有抢锁资格
// 饥饿模式下,不能自旋
// 锁被占用了,不能自旋
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// woken位没有被设置;被阻塞等待goroutine的个数大于0
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
// 可以自旋了,那就设置上woken位,在unlock时,如果发现有别的goroutine在自旋,就立即返回,有被阻塞的goroutine也不唤醒了
awoke = true
}
// runtime_doSpin -> sync_runtime_doSpin
// 每次自旋30个时钟周期,最多120个周期
runtime_doSpin()
iter++
old = m.state
continue
}
// 自旋完了还是等不到锁 或 可以上锁
new := old
// 饥饿模式下的锁不抢
if old&mutexStarving == 0 {
// 非饥饿模式下,可以抢锁
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
// 已经被上锁了,或锁处于饥饿模式下,就阻塞当前的goroutine
new += 1 << mutexWaiterShift
}
if starving && old&mutexLocked != 0 {
// 当前的goroutine已经被饿着了,所以要把锁设置为饥饿模式
new |= mutexStarving
}
if awoke {
// 当前的goroutine有自旋过,但现在已经自旋结束了。所以要取消woken模式
if new&mutexWoken == 0 {
panic("sync: inconsistent mutex state")
}
// 取消woken标志
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
// 成功上锁
break // locked the mutex with CAS
}
// 主要是为了和第一次调用的Lock的g划分不同的优先级
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 使用信号量阻塞当前的g
// 如果当前g已经阻塞等待过一次了,queueLifo被赋值true
runtime_SemacquireMutex(&m.sema, queueLifo)
// 判断当前g是否被饿着了
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
// 饥饿模式下,被手递手喂信号量唤醒的
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
panic("sync: inconsistent mutex state")
}
delta := int32(mutexLocked - 1<<mutexWaiterShift) // -7(111)
if !starving || old>>mutexWaiterShift == 1 {
// 退出饥饿模式
// 饥饿模式会影响自旋
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
// 不是手递手的信号量,那就自己继续竞争锁
// 必须设置为true,这样新一轮的CAS之前,就可以取消woken模式。
// 因为通过信号量释放锁时,为了保持公平性,会同时设置woken模式。
awoke = true
iter = 0
} else {
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if (new+mutexLocked)&mutexLocked == 0 {
// 不能多次执行unclock()
panic("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
// 非饥饿模式
old := new
for {
// 没有被阻塞的goroutine。直接返回
// 有阻塞的goroutine,但处于woken模式,直接返回
// 有阻塞的goroutine,但被上锁了。可能发生在此for循环内,第一次CAS不成功。因为CAS前可能被新的goroutine抢到锁。直接返回
// 有阻塞的goroutine,但锁处于饥饿模式。可能发生在被阻塞的goroutine不是被唤醒调度的,而是被正常调度运行的。直接返回
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 有阻塞的goroutine,唤醒一个或变为没有阻塞的goroutine了就退出
// 这个被唤醒的goroutine还需要跟新来的goroutine竞争
// 如果只剩最后一个被阻塞的goroutine。唤醒它之后,state就变成0。
// 如果此刻来一个新的goroutine抢锁,它有可能在goroutine被重新调度之前抢锁成功。
// 这样就失去公平性了,不能让它那么干,所以这里也要设置为woken模式。
// 因为Lock方法开始的fast path,CAS操作的old值是0。这里设置woken模式成功后,后来者就只能乖乖排队。保持了锁的公平性
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false)
return
}
old = m.state
}
} else {
// 饥饿模式
// 手递手唤醒一个goroutine
runtime_Semrelease(&m.sema, true)
}
}
|