现代操作系统-笔记
本文整理了在学习操作系统储存管理过程中的一些知识点和思考。如有错漏,还望指正。
本文长期保持更新
存储管理
储存管理实际上就是内存管理。关于这块,通过以下几个问题来理清当中重要的概念。
- 什么是虚拟内存
- 什么是分页
- 什么是页表
- 在分页式系统中,需要考虑的两个主要问题
- 什么是转换检测缓冲区(TLB)
- 多级页表
- 缺页中断问题
1.什么是虚拟内存
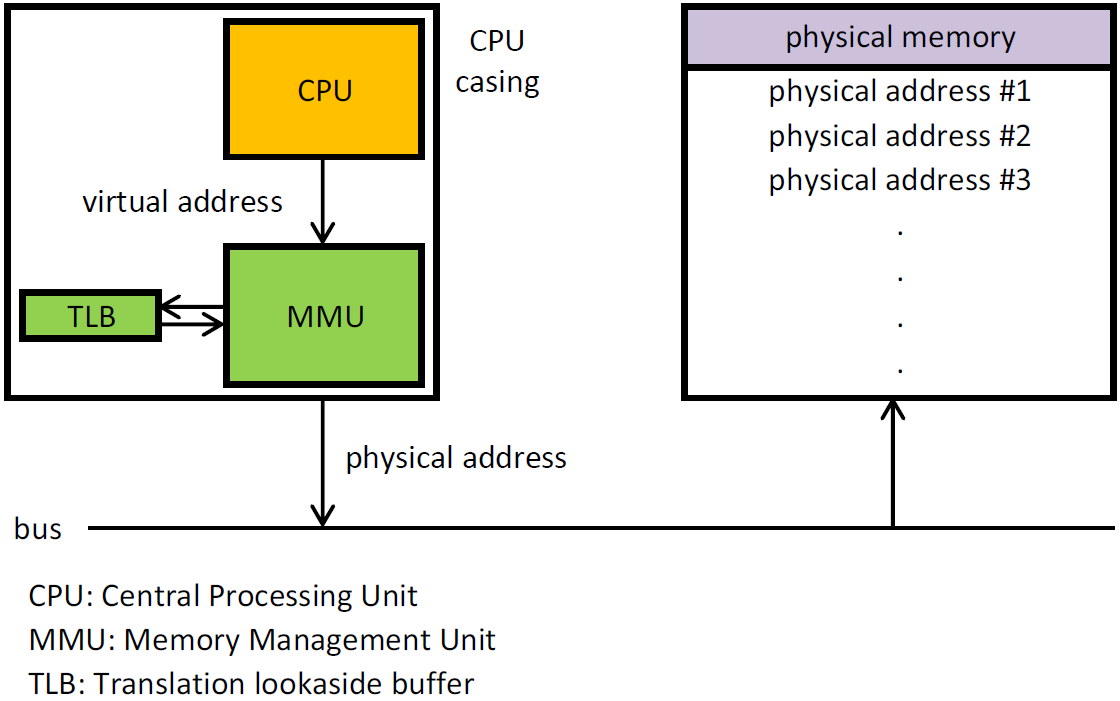
介绍虚拟内存前先介绍两个寄存器:
基址寄存器与界限寄存器 没有对内存进行抽象时,程序每条指令对应的都是一个绝对的物理内存地址,如果两个程序的某个操作都涉及到同一地址20上的数据,就会发生问题。所以没有内存的抽象是不能进行多程序设计的。在对内存地址进行抽象之后,引入了两个寄存器。每次进程要要访问内存某个地址上的数据时,都需要先将进程发出的地址加上基址寄存器,然后与界限寄存器作比较,合法则把值送到内存总线上。
虚拟内存就是对地址空间的抽象,它的对象是进程,欺骗进程,让进程觉得自己是在一段连续地址空间上。使用虚拟内存的其中一个好处就是“小内存可以运行大作业”。就是内存为32KB的机器可以运行64KB大小的程序。利用的正是虚拟内存的动态加载技术。
虚拟内存基本思想:每个程序拥有自己的地址空间,这个空间被分割乘多个块,每一个块也就是一页。每一页有连续的地址范围。这些页都被映射到物理内存上,但只需程序引用到的页在物理内存就可以了,不需要把页全部装入。当引用到的页不在物理内存时,才由操作系统负责将缺失的页调入到物理内存中。接着重新运行失败的指令。
最初虚拟内存是与交换技术具有一样作用,就是为了解决物理内存容量满足不了程序大小增长的需求。交换技术的原理就是把不运行的进程从内存中放到磁盘上以致于腾出内存空间供别的进程运行。交换技术就很好地利用了基址寄存器和界限寄存器。可它的问题是,每次都需要全部装入全部移出。与之相比,虚拟内存利用分页技术,把需要的那一部分的代码驻于内存中足以,暂时不需要的就放在磁盘中。
交换技术的缺点是:它会造成内存空洞,需要用到内存紧缩的方法去解决空洞。可是内存紧缩技术十分地消耗CPU,所以一般不采用。
与虚拟内存有关的两个简单概念:
- 虚拟地址
- 虚拟地址空间 虚拟地址是由程序产生的。例如** MOV REG, 3451 或者通过CS + IP取的下一条执行指令地址,都是虚拟地址。而由这些虚拟地址构成虚拟地址空间**。
在虚拟内存的概念下,物理地址的产生是需要一个叫内存管理单元(MMU)的硬件。由它把虚拟内存转换为物理地址。
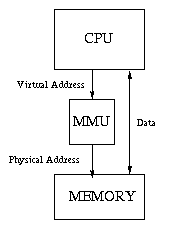
2.什么是分页
将虚拟地址空间按固定的大小(例如4KB)划分成称为页面的若干单元。在物理内存中对应的单元称为页框。页面的大小通常和页框的大小一致。
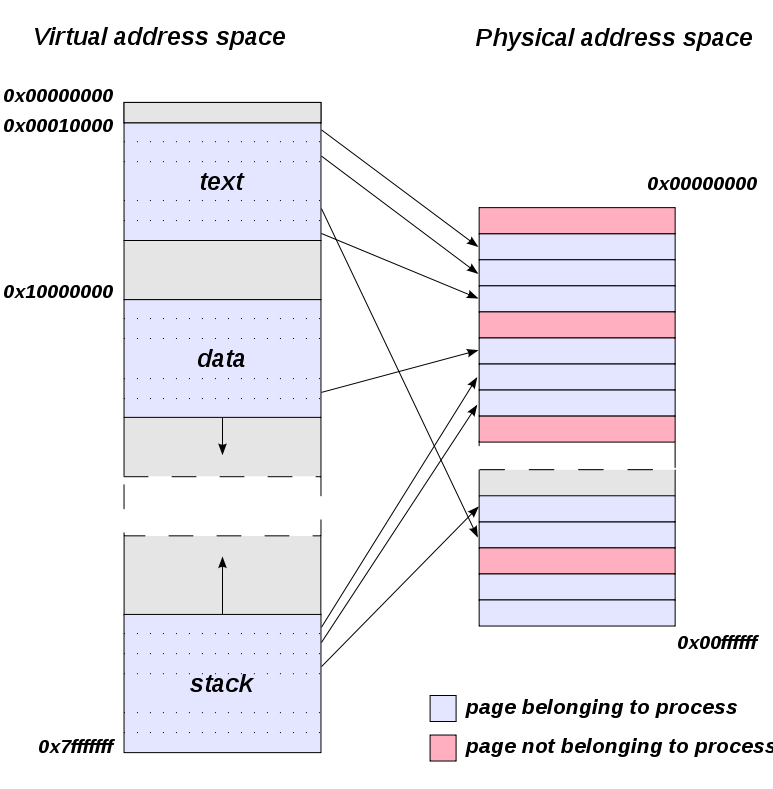
一个进程经过这样分页之后,就可以灵活地不必按序地存在空闲的内存空间上。这样做能够减少内存的碎片化。
分页技术的发明是为了获得更大的线性地址空间而不必购买更大的物理储存器。
3.什么是页表
但是分页之后,如何去定位到物理地址呢?页表就是解决这个问题的。
每个进程度会有自己的页表。页表里存放的是虚拟页号和对应页框的关系。通过页号找到对应页表项,页表项中存放着页框号和一些标志位。页表项常用的大小是32位。
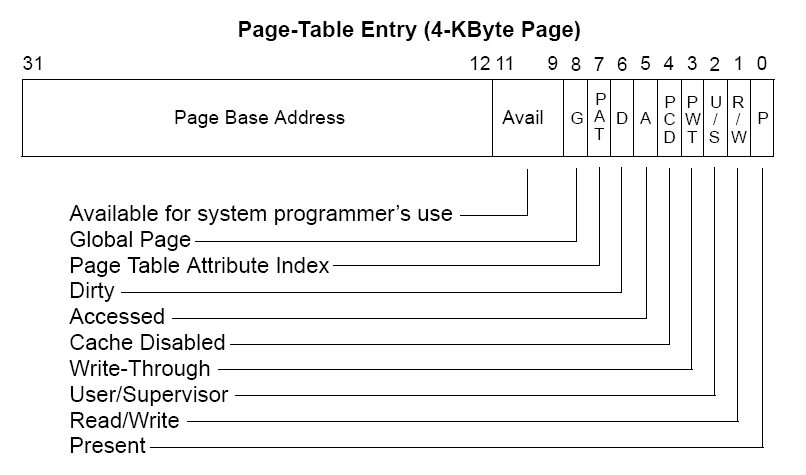
16位的虚拟地址被拆分为高4位页框和低12位的页内偏移地址。通过高4位页号定位到页框号,然后将页框号加上低12位的页内偏移地址就可以得到物理地址。
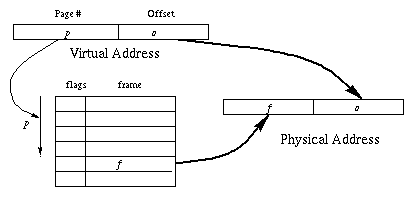
页表最初是放到MMU中,后来页表被存放到内存中,用一个寄存器指向页表的位置。
4.在分页式系统中,需要考虑的两个主要问题
考虑问题的解决方法好不好时,问题规模增大的情况是一个不可避免的考虑因素。同样地,随着虚拟地址空间的增大,页表会很大,并且虚拟地址转物理地址的速度也要保证足够的快。 因此,在分页式系统中就要解决两个问题:
- 地址转换的速度
- 页表增大的问题
这两个问题分别可以通过TLB和多级页表的方法进行解决。
5.什么是转换检测缓冲区(TLB)
TLB就是为解决地址转换速度而生的。如果不用TLB,会有什么问题? 我们知道CPU会从内存中获取指令和数据,而每次获取的时候都需要访问页表进行定位,也就是说,每次内存访问都需要额外的两次页表内存访问。这样做会降低了一半的性能。
为了解决这个问题,多年以来计算机学者都意识到一种现象:
大多数程序总是对少量的页面进行多次的访问,而不是相反的。
基于这个现象,那么就可以利用硬件做一个缓冲。
TLB中的表项一般不会多,在实际中很少会超过64个。每个表项除了有虚拟页号和页框号之外,还有一些标志位。

每次地址转换的时候,都是并行地在TLB中进行匹配。匹配成功则直接返回页框号,就不需要到页表中查询。匹配失败的情况(TLB失效)在后面介绍。
TLB管理
对于TLB的管理,有两种:
- 硬件管理
- 软件管理
硬件管理: 最开始是由硬件MMU进行管理的,包括TLB失效。当TLB失效时候,硬件去查找页表,然后更新TLB的表项,接着从失效处再次运行。这时因为更新了TLB表项,所以这次肯定会命中。如果硬件在页表中找不到的话,这时就发生缺页中断,陷入操作系统。操作系统进行磁盘IO操作,把缺失的页调进来之后,从中断处重新执行。接着就会更新TLB表项,再次从失效处重新运行。
软件管理: 而现代,许多的机器已经由软件进行TLB管理了。与硬件管理不同的是,发生TLB失效时,不再由硬件处理,而是直接交给操作系统处理,操作系统从页表中找,如果找不到就缺页中断,磁盘IO完毕之后再从中断处执行,直到把TLB表项更新完毕。
无论是用硬件还是软件来处理TLB失效,常见方法都是找到页表并执行索引操作以定位将要访问的页面。
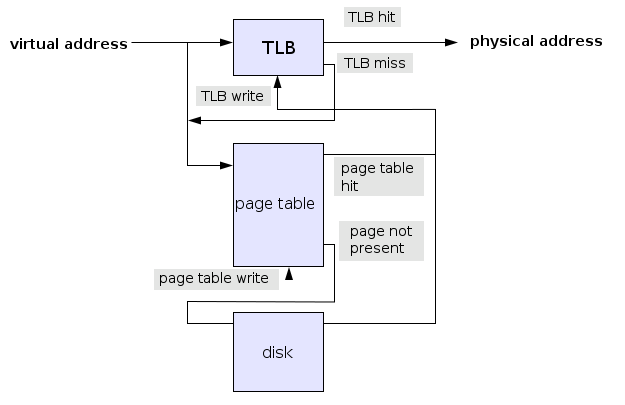
TLB失效时,在内存页表中寻找时,称为软失效。不需要磁盘IO处理,典型的处理需要10~20个机器指令。但是如果在内存页表中找不到需要磁盘IO处理时,称为硬失效,这个过程的处理时间往往是软失效的百万倍!
典型的TLB
- 寻中时间:0.5 - 1 时钟频率周期
- 不命中代价:10 - 30 时钟频率周期
- 不命中率: 0.01% - 3%
6.多级页表
考虑到虚拟内存空间的增大会带来页表的增大,所以必须解决这问题。
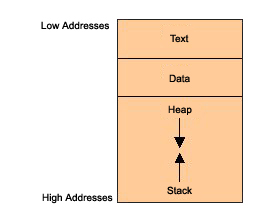
如果观察进程在内存中的布局,不难发现进程申请的内存中有大部分的空间是未使用到的,例如堆和堆栈都是动态增长的。所以那未使用到的内存对应的页表完全可以不加载进来,放到磁盘上。
把原来的一级页表转为二级页表就可以解决问题。甚至可以转为三级页表,但超过三级页表就会带来更大的复杂性。liunx使用的就是三级页表。
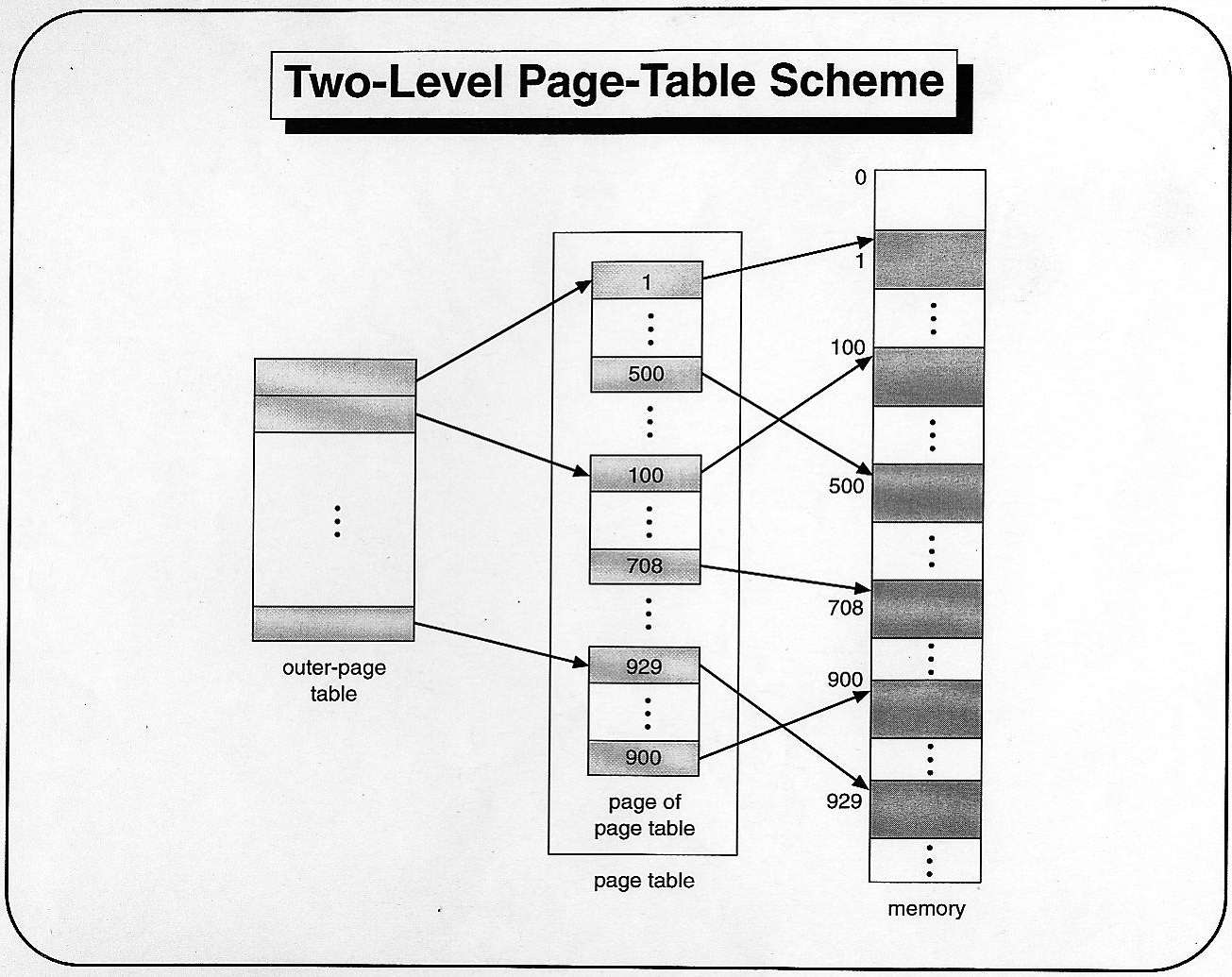
可以看到顶级页表中间索引到的页表可以不加载进内存当中来,需要的时候再加载。
引入多级页表的原因是避免把全部页表一直保存在内存中。
使用多级页表的方式,虚拟地址的构造解析自然就需要改变,不再是页号:偏移地址的形式了。在二级页面中,虚拟地址被划分为顶级页表:二级页表:偏移量的形式。
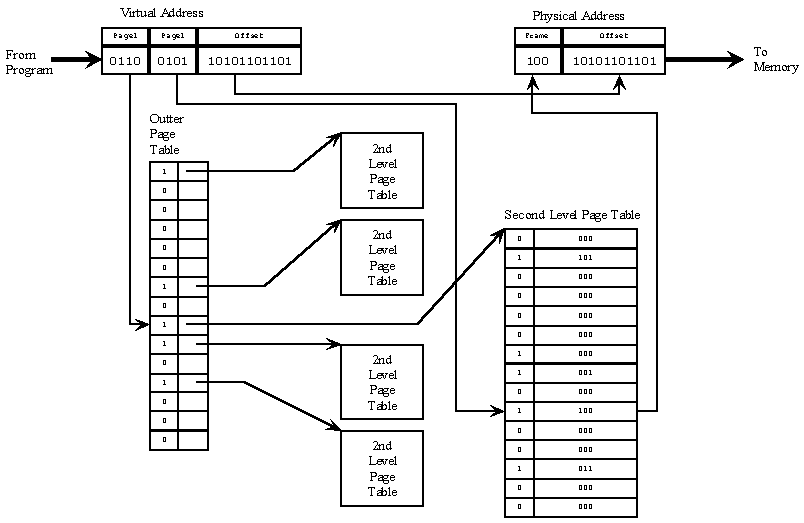
二级页表的转换机制见上图,而其他的三级页表、多级页表同理。
而在64位的机器上,由于地址线为64位。页表的容量十分地大,如果每一个表项8个字节,整个页表就会超过30PB。 解决这个问题的方案之一是倒排页表。
倒排页表就是在实际内存中每一个页框有一个表项,而不是每一个虚拟页面有一个表项。
倒排页表存在的缺点是其虚拟地址的转换会变得困难。
7.缺页中断问题
当发生缺页中断的时候,操作系统需要从内存中选出一个页面将其调出,然后加载进新的页面。
好的页面置换算法能提高CPU的性能。
常用的页面置换算法有:
- 最佳置换算法 (Optimal)
- 先进先出 (Fiset In First Out)
- 最近未使用 (No Used Recently)
- 最近最久未使用 (Last Recently Used)
- 最近不经常使用 (Not Frequently Used)
- 老化算法
最佳置换算法(OPT)
这个算法不可能实现,但它能作为别的算法一个十分好的参考。
算法的思想是:
在页面置换时,选择的老页面要在最远的将来才会被访问得到。
因为它需要预知一些页面的在往后的什么时候或者是多少条指令后会再被执行,所以不可能实现。
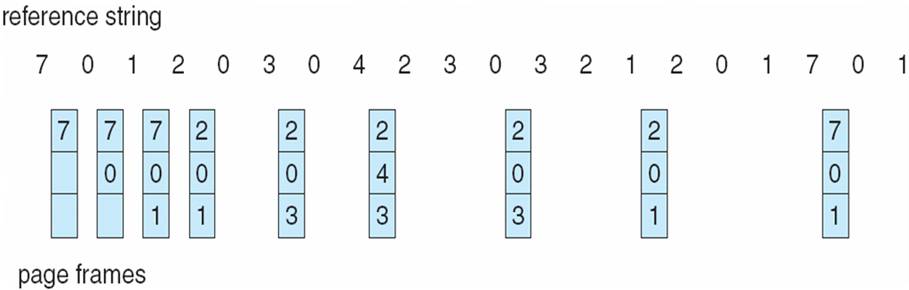
图片上面的数字意思是下一条指令需要用到的页面号。
可以通过仿真,预先执行一次,获得页面的走向,以用于与别的算法进行性能比较,作一个参考。
先进先出(FIFO)
先进先出的思想就是先进来的页面在缺页置换的时候会被先调出去。
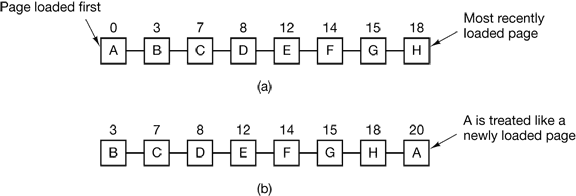
但是纯粹的先进先出算法可能会淘汰出一些常用页面,所以要对它进行改进一下。
改进的方法叫做第二次机会。思想是在必须换出页面的时候,给该页面第二次机会。检查该页面的R位是否为1,如果是,则将该页面放到队尾。如果是0,则直接换出。假如全部检查一轮后全都没有被换出,那样就换出第一个被检查的页面。
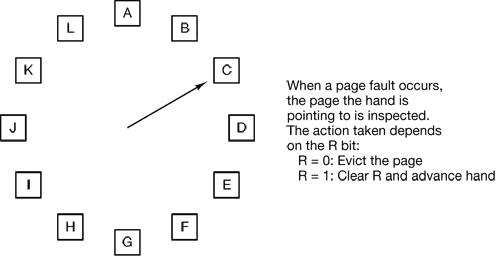
第二次机会算法需要经常去移动结点,这样造成效果不高。改进的方法可以把链表做成环链。用一个指针指向队头,每次换出时检查指针指向页面的R位,如果为0直接换出,否则,置0后,指针前移,一直重复,直到找到R位为0的页面为止。
最近未使用(NRU)
这个算法需要为每一个页面设置两个位,一个是被访问,另一个是被修改。 这两个位的值都是由硬件设置的。 被访问位会被定期的清零。例如是每次的时钟中断时。这样的话,这个位的值在发生缺页中断就会提供一个很好的参考价值。
那么根据这两个位,一个页面可能会存在的状态就会有:
- (第一类)没有被访问, 没有被修改
- (第二类)没有被访问, 已被修改
- (第三类)已被访问, 没有被修改
- (第四类)已被访问, 已被修改
那么当发生缺页中断时:
淘汰一个没有被访问但已修改的页面要比一个经常被访问但没被修改的页面要好。
所以,页面置换的时候,根据现在内存中进程页面的状态,从最小类别的页面中随机选择一个页面将其淘汰掉。 例如: 存在第一类,就随机淘汰属于这类的页面。如果没有,就寻找第二类的,以此类推。
NRU算法的优点是比较好理解和实现,但是性能不是最优。
最近最久未使用(LRU)
LRU算法它基于这种的一个思想:
LRU works on the idea that pages that have been most heavily used in the past few instructions are most likely to be used heavily in the next few instructions too.
最近频繁使用的页面在未来的指令中仍会被使用,反过来,很久没使用过的页面在未来的较长一段时间里仍然不会被使用。
这个思想是这样理解的:在需要的换页时,我们认为在换页发生前所执行的几条指令在未来仍会执行。而在更远前的几条指令在未来的较长时间里不会被执行。
实现这个算法,就需要去维护每个页面的使用情况这样一个链表。这个链表放在内存中,较多使用的放在链表头,较少的就放在链表尾。然而每次访问页面的时候都需要去更新这个链表,移动结点,这样带来的开销十分大,代价高。
那么,可以通过使用特殊的硬件去实现LRU,直接通过硬件就可以选择出最近最久未使用的页面。问题并不是每台PC都有这样一个硬件。所以就需要用软件去模拟LRU算法,那就是最近不常用算法(NFU)。
最近不经常使用(NFU)
这个算法只是一个非常粗鲁地LRU软件模拟硬件的算法。 它的思想是,每个页面有一个counter的计数器。这个计数器会在系统每次时钟中断的时候由操作系统修改,怎样修改呢?操作系统会把该页面上的R位的值加在counter上面,以此来跟踪页面。所以在选择换出页面的时候,就选择counter最小的页面。
因为这个算法只是LRU的相对粗略的近似,所以其性能只是一般。
老化算法
老化算法是针对NFU的改进。NFU的问题在于它会一直的记录,这样可能会造成有用的页面反而被置换出去了。
老化算法根据每次时钟中断时页面的R位去设置一个计数器。设置的方法是将计算器右移一位,然后把R位的值放到最左边。在换页的时候就选择计数器最小值的页面。 详细的介绍可以参考这里
针对老化算法中计数器的位数不足问题。其实在实践中,如果时间滴答是20ms,8位一半是够用的。假如一个页面已经有160ms没有被访问过,那么它很可能并不重要。
未完
文章中使用到的图片均来源于网络
参考